Schrijver:
John Stephens
Datum Van Creatie:
1 Januari 2021
Updatedatum:
1 Juli- 2024

Inhoud
In statistieken, modus van een reeks getallen is nummers komen het vaakst voor in die populatie. Een dataset hoeft niet slechts één modus te hebben - als twee of meer waarden als de meest voorkomende worden beschouwd, kan die dataset worden aangeroepen bimodaal (twee modi) of multimodaal (multimode) - met andere woorden, alle meest voorkomende waarden zijn de modus van de set. Zie stap 1 hieronder om aan de slag te gaan voor details over het bepalen van de modus van een dataset.
Stappen
Methode 1 van 2: Zoek de modus van een gegevensset
Maak een lijst van de nummers in uw dataset. Modi worden vaak verkregen uit statistische gegevenspuntsets of een lijst met numerieke waarden. Dus om een modus te vinden, heb je een dataset nodig om naar te zoeken. Het is moeilijk om moduswaarden te berekenen door alleen te visualiseren, behalve voor de gegevenssets die te klein zijn, dus in de meeste gevallen is de verstandigste manier om uw gegevensset te schrijven (of te typen). . Als u met papier en potlood werkt, schrijft u de waarden in uw dataset op volgorde, terwijl u een rekenmachine gebruikt, moet u wellicht een Excel-programma gebruiken.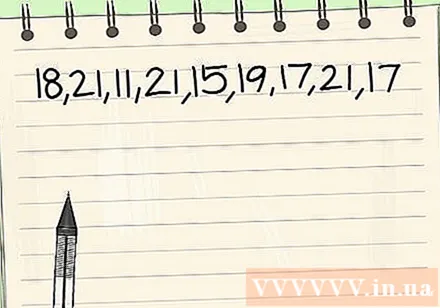
- Het proces van het vinden van de modus van een gegevensset is gemakkelijker te begrijpen als het wordt geïllustreerd met een voorbeeld. Laten we in deze sectie de volgende reeks waarden als voorbeeld gebruiken: {18, 21, 11, 21, 15, 19, 17, 21, 17}. In de volgende stappen zullen we de modus van deze verzameling vinden.

Sorteer de cijfers van klein naar groot. Het is verstandig om de waarden van de dataset in oplopende volgorde te rangschikken. Hoewel dit optioneel is, wordt het proces van het vinden van de modus gemakkelijker omdat vergelijkbare waarden naast elkaar worden gegroepeerd. Voor grote datasets is dit echt nodig, omdat het moeilijk is om lange lijsten te categoriseren en te onthouden hoe vaak elk nummer in de lijst voorkomt en dit tot fouten kan leiden.- Als u met papier en potlood werkt, kunt u op de lange termijn tijd besparen. Ga door de reeks getallen om te zien welk getal het kleinste is, en als je het eenmaal hebt gevonden, start je de nieuwe dataset met dat kleinste getal, gevolgd door het tweede, het derde kleinste, enzovoort. Zorg ervoor dat elk nummer gelijk is aan het aantal keren dat het in de originele dataset is verschenen.
- Met de rekenmachine kunt u met een paar klikken zoeklijsten van klein naar groot sorteren
- In het bovenstaande voorbeeld zou na het sorteren onze nieuwe lijst zijn: {11, 15, 17, 17, 18, 19, 21, 21, 21}.

Tel het aantal keren dat elk nummer wordt herhaald. De volgende stap is om het aantal keren te tellen dat elk nummer in de set voorkomt.Zoek de waarde die het vaakst voorkomt in de gegevensset. Voor relatief kleine datasets waarvan de punten in oplopende volgorde zijn gesorteerd, is het vinden van "clusters" met vergelijkbare waarden en het tellen van hun voorkomen relatief eenvoudig.- Als u met papier en een potlood werkt, onthoud dan uw telling en noteer hoe vaak elke waarde voorkomt op elk cluster met hetzelfde nummer. Als u een Excel-desktopprogramma gebruikt, kunt u hetzelfde doen door ze in het vak ernaast te schrijven of door een van de programmafuncties te gebruiken om gegevenspunten te tellen.
- In ons voorbeeld ({11, 15, 17, 17, 18, 19, 21, 21, 21}) komt 11 één keer voor, 15 komt één keer voor, 17 komt twee keer voor, 18 komt één keer voor. eenmaal, 19 verschijnen eenmaal, en 21 verscheen drie keer. 21 is de meest voorkomende waarde in deze dataset.

Bepaal de waarde die het vaakst voorkomt. Als u weet hoeveel exemplaren elke waarde voorkomt, zoekt u de waarde met de meeste exemplaren. Dit is de modus van uw dataset. Let daar op Een dataset kan meer dan één modus bevatten. Als twee waarden het meeste voorkomen in de populatie, is de set bimodaal (twee modi), als er drie van dergelijke waarden zijn, is de set trimodaal (drie modi), enzovoort.- In het bovenstaande voorbeeld, ({11, 15, 17, 17, 18, 19, 21, 21, 21}), aangezien 21 hoogstens voorkomt, 21 is de modus.
- Als een meer waarde heeft dan 21 ook komt drie keer voor (er zijn bijvoorbeeld 17 extra in de set), dan 21 en dit nummer beide zal de modus zijn.
Verwar de modus niet met het gemiddelde of de mediaan. Drie statistische begrippen die vaak samen worden genoemd, zijn gemiddeld, mediaan en modus. Omdat deze begrippen gelijk klinkende namen hebben, en omdat in een dataset soms een waarde kan worden gesloten. meer dan een rollen in deze nummers, dus het is gemakkelijk om ze te verwarren. Ongeacht of uw gegevensset modi heeft of niet, deze heeft altijd een mediaan of gemiddelde. Het is belangrijk om te begrijpen dat deze drie concepten volledig onafhankelijk van elkaar zijn. Zie hieronder:
- Gemeen van een dataset is het gemiddelde van die set. Om het gemiddelde te vinden, tel je alle waarden in de set bij elkaar op en deel je de som door het aantal termen in de set. Bijvoorbeeld de eerste reeks getallen ({11, 15, 17, 17, 18, 19, 21, 21, 21}), het gemiddelde is 11 + 15 + 17 + 17 + 18 + 19 + 21 + 21 + 21 = 160/9 = 17.78. 9 betekent dat er 9 cijfers in de set zitten.

- Mediaan van een dataset is het "middelste getal" dat de kleine en grote waarden van die set in twee gelijke helften verdeelt. Neem het bovenstaande voorbeeld, ({11, 15, 17, 17, 18, 19, 21, 21, 21}) 18 is mediaan omdat het het middelste getal is - er zijn precies vier getallen hoger dan dit getal en vier getallen lager. Merk op dat als het aantal waarden in de set even is, de mediaan het rekenkundig gemiddelde is van de twee middelste getallen.

- Gemeen van een dataset is het gemiddelde van die set. Om het gemiddelde te vinden, tel je alle waarden in de set bij elkaar op en deel je de som door het aantal termen in de set. Bijvoorbeeld de eerste reeks getallen ({11, 15, 17, 17, 18, 19, 21, 21, 21}), het gemiddelde is 11 + 15 + 17 + 17 + 18 + 19 + 21 + 21 + 21 = 160/9 = 17.78. 9 betekent dat er 9 cijfers in de set zitten.
Methode 2 van 2: Zoekmodus in speciale gevallen
In datasets waarin elke waarde een gelijk aantal keren voorkomt, is er geen modus. Als waarden in een bepaalde set hetzelfde aantal keren voorkomen, heeft deze dataset geen modus omdat er geen nummer meer voorkomt dan enig ander. Gegevenssets waarin elke waarde slechts één keer voorkomt, hebben bijvoorbeeld geen modus. Hetzelfde geldt voor gegevenssets met waarden die tweemaal, driemaal voorkomen, enzovoort.
- Als we de voorbeeldgegevensset wijzigen in {11, 15, 17, 18, 19, 21} zodat elke waarde maar één keer voorkomt, wordt deze gegevensset nu Er is geen modus. Dit is hetzelfde als we de dataset wijzigen zodat elke waarde twee keer voorkomt: {11, 11, 15, 15, 17, 17, 18, 18, 19, 19, 21, 21}.
De modus van niet-numerieke gegevenssets kan op dezelfde manier worden gevonden als voor numerieke gegevenssets. Over het algemeen zijn de meeste datasets Kwantitatief - ze bevatten numerieke gegevens. Sommige datasets bevatten echter informatie die niet als een getal wordt weergegeven. In deze gevallen is "mode" nog steeds de meest voorkomende waarde in die dataset, net als in numerieke datasets. In deze gevallen is het vinden van de modus mogelijk, terwijl het vinden van de mediaan of het gemiddelde niet mogelijk is.
- Neem een voorbeeld in het biologische onderzoek om de boomsoorten in de regio te identificeren. De dataset voor de soorten bomen in de regio zijn {Bang, Phuong, Bang, Thong, Bang, Bang, Phuong, Phuong, Thong, Bang}. Dit type dataset wordt een dataset genoemd Naam omdat gegevenspunten alleen worden onderscheiden op basis van hun naam. De modus van de dataset is Bang omdat het het meest verschijnt (vijf keer terwijl Phuong drie keer verschijnt en Thong twee keer).
- In het bovenstaande voorbeeld kunt u het gemiddelde of de mediaan niet berekenen omdat de gegevenspunten niet numeriek zijn.
Voor symmetrische verdelingen met een modus vallen de modus, het gemiddelde en de mediaan samen. Zoals hierboven opgemerkt, kunnen de modus, de mediaan en / of het gemiddelde onder bepaalde omstandigheden hetzelfde zijn. In gevallen waarin de dichtheidsfunctie van de dataset een perfect symmetrische curve vormt met één modus (bijv. De Gauss-curve of de "Bell Curve"), dan zijn de modus, het gemiddelde en de mediaan dezelfde waarde. Omdat de verdelingsfunctie het relatieve voorkomen van de gegevenspunten zal plotten, bevindt de natuurlijke modus zich in het midden van de symmetrische verdelingskromme, aangezien dit het hoogste punt van de grafiek is en overeenkomt met de waarde. meest populair. Omdat de dataset symmetrisch is, komt dit punt in de grafiek overeen met de mediaan (middelste waarde van de dataset) en het gemiddelde (het gemiddelde van de dataset).
- Beschouw het volgende voorbeeld {1, 2, 2, 3, 3, 3, 4, 4, 5}. Als we de verdeling van deze dataset plotten, krijgen we een symmetriecurve van hoogte 3 op x = 3 en omlaag naar 1 op x = 1 en x = 5. Aangezien 3 de prijs is behandeling meestal, het is de modus. Omdat de middelste 3 waarde van de set 4 waarden aan elke kant heeft, 3 ook de mediaan. Ten slotte is het gemiddelde van de populatie 1 + 2 + 2 + 3 + 3 + 3 + 4 + 4 + 5 = 27/9 = 3, wat betekent dat 3 is ook een gemiddelde.
- De uitzondering op deze regel is dat symmetrische datasets meer dan één modus hebben - in dit geval, aangezien er slechts één mediaan en gemiddelde is voor die dataset, zullen beide modi niet samenvallen met de andere punten. .
Advies
- U kunt meer dan één modus hebben.
- Als alle cijfers maar één keer verschijnen, is er geen modus.
Wat je nodig hebt
- Papier, potlood en gum



